September 2024 — the FUD surrounding model scaling and performance returns filled the X/Twitter zeitgeist. The Information contributed to scaling fears with leaks regarding OpenAI Orion's performance (eventually, GPT-4.5) and Anthropic's delay in releasing Claude 3.5. Without the release of OpenAI's incredible o1 model, the wave of fear might have consumed everyone.
Semianalysis published a rebuttal to the scaling fear later in December. The internet is split between pre-training being over to US training missing optimizations ala DeepSeek V3.
Here's my theory on the current state of scaling:
The next step is 1M H100 equivalents — coupled with better post-training and reasoning, but few labs can continue at this scale.
Grok 3 capabilities
Grok 3 is currently the only frontier model trained on over 100k colocated H100s.
Grok 3 demonstrates significant intelligence over other frontier models (Gemini 2.5, GPT-4o, and Claude 3), especially with regards to smarter coding decisions with fewer lines and less bloat/creep.
But the model struggles with small bugs in language to language translation, function calling, instruction following (especially within multi-turn threads), and coding diffs.
Grok 3's flaws showcase the post-training regime leads at OpenAI, Google, and Anthropic compared to xAI.
Stargate
OpenAI's urgency to move away from Microsoft and onto their own colocated cluster, Stargate, signals their belief in the value of Colossus' scale.
Google has yet to announce their own Stargate-like program, yet Gemini continues to operate at the efficient frontier of cost/intelligence. Anthropic, tied to Amazon for training and inference scale as part of their recent fundraising, lacks the ability to operate at this scale.
updated price-elo pareto frontier with deepseek v3/r1 and gemini 2 flash thinking 2 results notes: - o1-mini and o3-mini are going to have to DRASTICALLY cut prices (like, at least 25x) to keep up. it is not a surprise that o3-mini is going to be in free chatgpt much sooner Show more
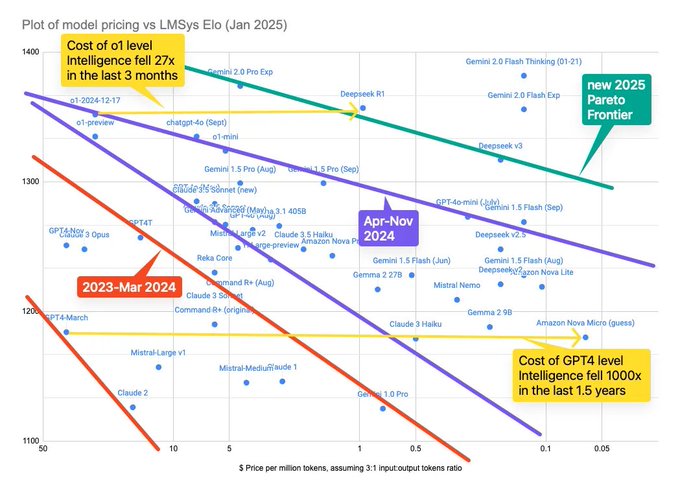
🆕 2025's biggest surprise so far: Reasoning is less of a moat than anyone thought. latent.space/p/reasoning-pr…
Update: May 22
Anthropic's release of Claude 4 appears to validate this theory. Claude 4, Sonnet and Opus, fall behind Gemini 2.5 in coding, at 2x the cost. Without a significant change to infrastructure, Anthropic will likely not keep pace with Google, OpenAI, and xAI.